深入浅出Disk-IO
Feb 25, 2023 - #Block Storage
了解IO的工作原理、应用场景以及算法的均衡考量,深入理解存储系统可以帮助开发者和操作人员更好的工作:他们可以根据他们正在评估的数据库底层来做出更好的决定。通过将它们的工作负载与他们选择的数据库进行比较,可以解决数据库行为不当时的性能问题,并调整它们的设计结构(通过负载均衡、切换到不同的介质、文件系统、操作系统,或选择一个不同的索引类型等等)。
如今网络的IO常常被讨论,而文件系统的IO似乎没有得到足够的关注。一部分原因是网络IO 有着很多特性以及实现细节,根据操作系统的不同而发生变化。然而文件系统的IO往往是一个比较小的工具集合,同时,在现代系统中人们常用数据库作为存储工具,应用通过数据库提供的驱动经过网络互相交流,而文件系统IO则是留给了数据库开发人员理解以及使用。然而理解数据是怎么样被写到硬盘上以及如何从硬盘上读取仍然是一件非常重要的事情。
对于IO来说通常有几种方式(接口)
- 系统调用:open, write, read, fsync, sync, close
- 标准IO:fopen, fwrite, fread, fflush, fclose
- 向量化IO:writev, readv
- 内存映射IO:- open, mmap, msync, munmap
我们先从标准标准IO开始讨论,包括它的几个面向用户的优化,因为标准IO通常是应用程序开发者使用最多的。
Buffered IO
当谈论到stdio.h中函数的时候,“buffering”显得有些迷惑人。当你使用标准IO的时候,可以在全缓冲、行缓冲或者不使用任何缓冲等等方式中选择。这种“用户空间”的缓冲与内核缓冲无关(页缓存),你也可以认为缓冲(buffering)和缓存(caching)中存在不同,这可能会使得你对这些概念更加清晰。
Sector/Block/Page
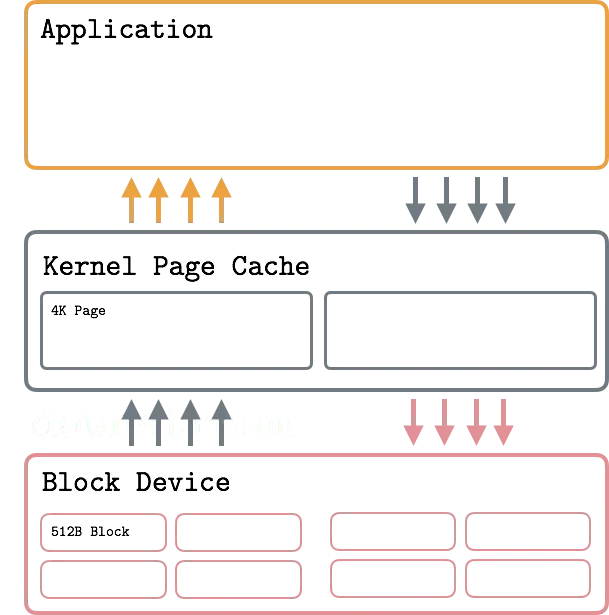
块设备是一个特殊的文件类型,它向硬件设备例如机械硬盘或者固态硬盘提供缓冲访问方式。块设备通过操作片区(Sector)来工作,Sector就是一些临近连续的字节。大多数硬盘设备将512字节作为Sector的大小。Sector是块设备传输设备的最小单元,传输一个小于Sector大小的数据是不可能的。然而,通常同时取用多个临近的段是可以的。文件系统中的最小可寻址单元是块(Block)。Block是被设备驱动请求的一些临近的Sector组。典型的块大小是512,1024,2048以及4096字节,通常IO是通过虚拟地址进行的,虚拟地址会将请求的文件系统块缓存在内存中,作为一个缓冲区提供快速的操作,虚拟内存是基于页表工作的,映射到文件系统的块中,典型的页(Page)大小是4096字节。
总的来说,虚拟内存中的Pages映射到文件系统中的Blocks,而Blocks又映射到块设备的Sectors
Standard IO
标准IO使用read()和write()系统调用来完成IO操作,当读取数据时,[Page Cache]首先被访问,如果数据不在cache中,则会触发一个[[缺页中断]],然后操作系统将需要访问的内容读取到Cache中来。这意味着读操作,如果访问没有被映射的部分将会花费更多的时间,缓存层对用户来说是透明的。
在进行写操作时,缓冲的内容首先被写进Page Cache中,这意味着数据并不是直接到达硬盘的,实际的硬件写入是在内核决定对dirty page执行一次writeback时进行的。
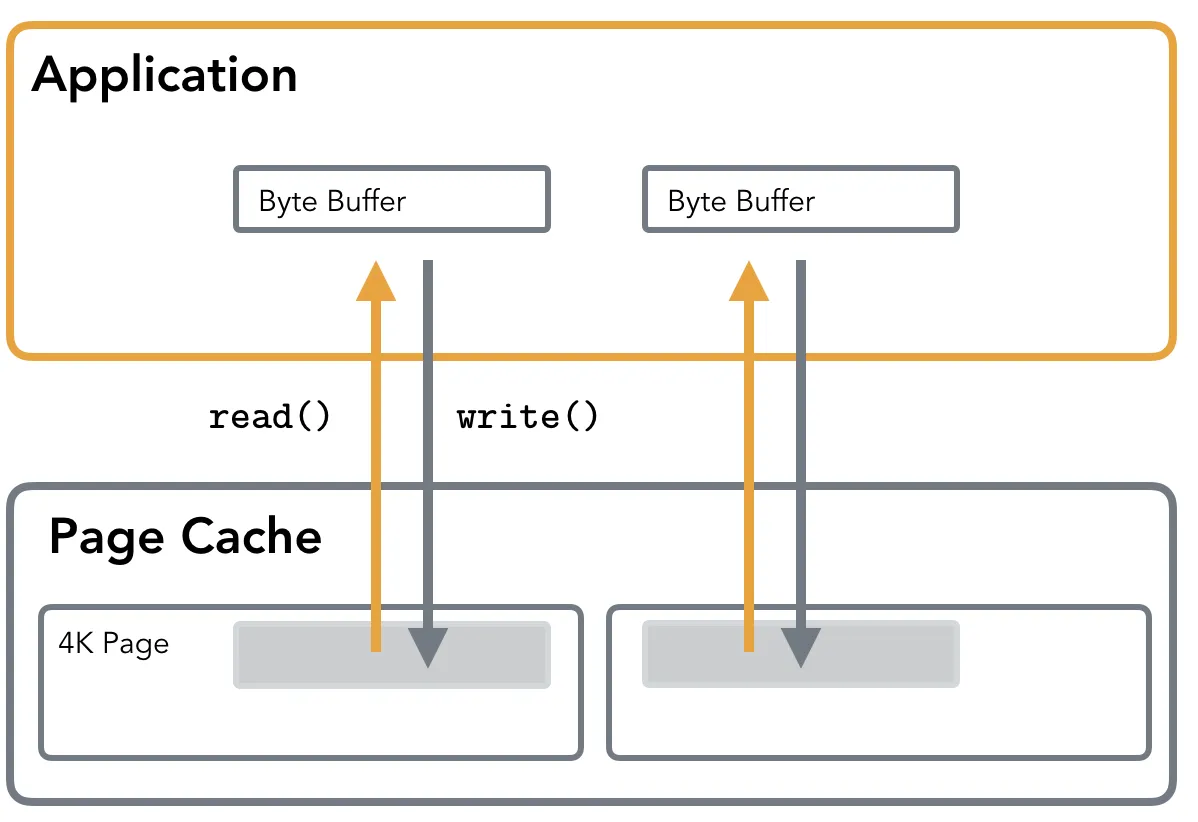
Page Cache
页缓存存储了被访问的文件中最有可能在最近的时间内被访问的片段,当操作硬盘文件时,read() and write() 调用不是直接访问硬盘而是通过Page Cache访问
执行读取操作时,首先查询页面缓存。如果数据已经加载到页面缓存中,就只用直接复制出来:不执行磁盘访问并且完全从内存读取。否则,文件内容将加载到页面缓存中,然后返回给用户。如果页面缓存已满,则最近最少使用的页面将刷新到磁盘上并从缓存中逐出以释放空间用于新页面。
write ()调用只是将用户空间缓冲区复制到内核 Page Cache,将写入的页面标记为dirty的。然后,内核在磁盘上写入修改,这个过程称为刷新或写回。实际的硬盘 IO 通常不会立即发生。同时,read ()将从 Page Cache 读取数据,而不是读取(现在已经过时的)磁盘内容。PageCache 在读和写时都被使用到。
标记为dirty的页将刷新到磁盘,因为它们在缓存上的内容现在不同于在磁盘上的内容。这个过程称为回写。Writeback 可能有潜在的缺点,比如会使得 IO 请求拥挤,因此在使用它时,有必要了解用于写回的阈值和比率,并检查队列深度,以确保可以避免节流和高延迟。可以在 Linux 内核文档中找到更多关于调优虚拟内存的信息。
Page Cache背后的逻辑可以用时间局部性原理来解释,即最近访问的页面将在最近的将来的某个时间点再次被访问。
另一个原则,空间局部性,意味着物理上临近的元素更有可能被连续访问。这个原则被用在一个称为“预取”的过程中,该过程提前加载文件内容,预期它们的访问并摊销一些 IO 成本。
Page Cache还会通过延迟写操作和合并相邻读操作来提高 IO 性能。
消除歧义: 缓冲区缓存和页面缓存: 以前是完全独立的概念,而在2.4 Linux 内核中得到统一。现在它主要被称为 Page Cache,但是一些人仍然使用术语 Buffer Cache,它成为同义词。
Page Cache 根据访问模式保存最近访问过的或者可能很快就会访问的文件块(预取或者用 fadvise 标记)。由于所有 IO 操作都是通过 PageCache 进行的,因此诸如读-写-读之类的操作序列可以从内存中提供,而不需要后续的磁盘访问。
当执行由内核或库缓冲区支持的写入时,确保数据实际到达磁盘(落盘)很重要,因为它可能在某处缓冲或缓存。当数据刷新到磁盘时会出现错误,这可能是在 fsyncing 或关闭文件时。如果您想了解更多信息,请查看 LWN 的文章确保数据到达磁盘。
Direct IO
在某些情况下,不需要使用内核页面缓存来执行 IO。在这种情况下,可以在打开文件时使用 O_DIRECT 标志。它指示操作系统绕过页面缓存,避免存储额外的数据副本,并直接对块设备执行 IO 操作。这意味着缓冲区直接刷新到磁盘上,而不需要首先将其内容复制到相应的缓存页面,然后等待内核触发写回操作。
对于使用 Direct IO 的“传统”应用程序来说,很可能会导致性能下降,而不是加速,但是在正确的情况下,它可以帮助获得对 IO 操作的细粒度控制,并提高性能。通常,使用这种 IO 类型的应用程序实现它们自己的特定于应用程序的缓存层。
内核开发人员通常不赞成使用 DirectIO。到目前为止,Linux 手册页引用了 Linus Torwalds 的话:
The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid”.
但是,PostgreSQL 和 MySQL 等数据库使用 Direct IO 是有原因的。开发人员可以确保对数据访问的细粒度控制,可以使用自定义 IO 调度器和特定于应用程序的缓冲区缓存。例如,PostgreSQL 使用 Direct IO For WAL (write-ahead-log) ,因为它们必须在确保持久性的同时尽可能快地执行写操作,并且可以使用这种优化,因为它们知道数据不会立即被重用,所以绕过 Page Cache 编写数据不会导致性能下降。
不建议使用 Direct IO 和 Page Cache 同时打开同一个文件,因为即使数据在 Page Cache 中,也会对磁盘设备执行直接操作,这可能会导致不希望看到的结果。
Block Alignment
由于Direct IO 涉及直接访问后备存储,绕过页面缓存中的中间缓冲区,因此要求所有操作都与扇区边界对齐。
换句话说,每个操作的起始偏移量必须是512的倍数,缓冲区大小也必须是512的倍数。在使用 Page Cache 时,因为写首先进入内存,对齐并不重要: 当执行实际的块设备写操作时,内核将确保将页分割成合适大小的部分,并对硬件执行对齐的写操作。


例如,RocksDB 通过前期检查确保操作是块对齐的(旧版本通过在后台对齐允许不对齐访问)。
无论是否使用 O_DIRECT 标志,确保读和写都是块对齐的总是一个好主意。跨越段边界将导致多个扇区从磁盘加载(或写回) ,如上图所示。使用块大小或恰好适合块内部的值可以保证块对齐的 I/O 请求,并防止内核中的无用工作。
Memory Mapping
内存映射(mmap)允许你访问一个文件,就好像它完全在内存中一样。它简化了文件访问,并经常被数据库和应用程序开发人员使用。
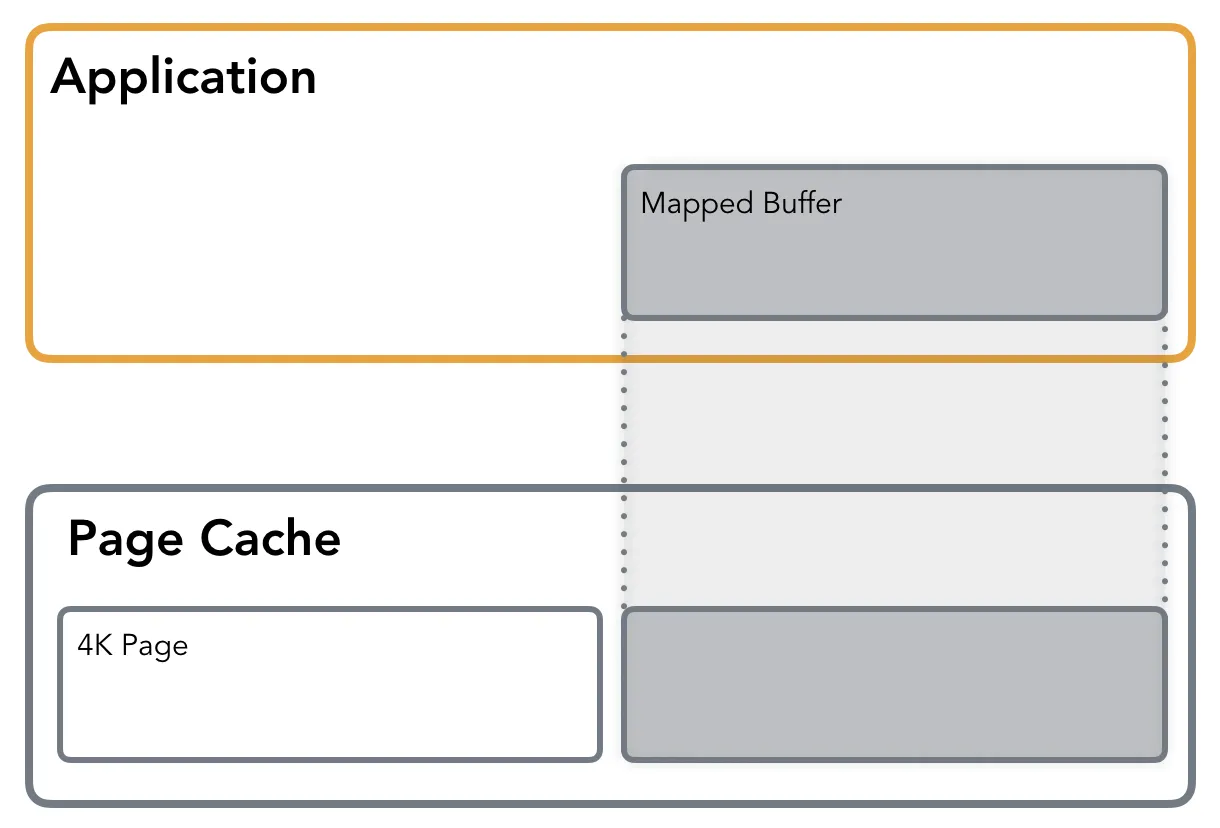
使用 mmap,文件可以私有地映射到内存段,也可以在共享模式下映射到内存段。私有映射允许从文件读取,但是任何写操作都会触发页面的写时复制(copy-on-write) ,以保持原始页面的完整性并保持更改的私有性,所以任何更改都不会反映在文件本身上。在共享模式下,文件映射与其他进程共享,这样它们就可以看到映射内存段的更新。此外,更改会传递到底层文件(需要使用 msync 进行精确控制)。
除非另有说明,否则文件内容不会立即加载到内存中,而是以惰性方式加载。内存映射所需的空间已保留,但不会立即分配。第一次读取或写入操作会导致Page Fault,从而触发相应页面的分配。通过传递 MAP_POPULATE 标记,可以预先对映射区域进行处理并强制提前读取文件。
这种惰性加载的方式在标准IO中同样也会被用到,因为标准IO也是通过Page Cache进行的,通常被称为demand paging。在第一次内存访问期间,将发出一个 Page Fault,它向内核发出信号,表明请求的页当前没有加载到内存中,因此必须加载。内核识别哪些数据必须从哪里加载。Page Fault对于开发人员来说是透明的: 程序流将继续进行,就像什么都没有发生一样。有时,页面错误可能会对性能产生负面影响
还可以使用保护标志(例如,只读模式)将文件映射到内存中。如果对映射内存段的操作违反了保护规则,就会引发Segmentation Fault。
Mmap 是使用 IO 的一个非常有用的工具: 它避免在内存中创建多余的缓冲区副本(不像标准 IO,在进行系统调用之前,数据必须复制到用户空间缓冲区中)。此外,它还避免了触发实际 IO 操作的系统调用(以及随后的上下文切换)开销,除非出现Page Fault。从开发人员的角度来看,使用映射文件发出随机读操作看起来就像一个正常的指针操作,并且不涉及 lseek 调用。
大多数时候提到的 mmap 的缺点在现代硬件的工作下已经关系不大了:
- Mmap 增加了管理内存映射所需的内核数据结构的开销: 在今天的实际情况和内存大小中,这个参数不起主要作用。
- 内存映射文件大小限制: 大多数情况下,内核代码对内存更加友好,并且64位架构允许映射更大的文件。
当然,这也不是说任何时候[[共享内存]]文件都是合适的。
数据库引擎设计人员经常使用 mmap。例如,MongoDB 默认存储引擎是 mmap 支持的,而 SQLite 广泛使用内存映射。
从目前来看,使用标准IO似乎简化了很多问题,并且有很多好处,但代价是失去了完全的控制:你在内核和page cache的帮助下工作的很好。在某些情况下,这确实是真的。通常,内核可以使用内部统计信息更好地预测何时执行回写和预取页面。但是,有时可以从应用程序的角度考虑,来帮助内核以对应用程序有利的方式管理页面缓存。
将您的意图通知内核的一种方法是使用 fadvise。使用这个标志,可以向内核说明你的意图,并让它优化页面缓存的使用:
- FADV_SEQUENTIAL 指明该文件是按顺序读取的,从较低的偏移量读取到较高的偏移量,因此内核可以确保在实际读取发生之前提前获取页面。
- FADV_RANDOM 禁用预先读取,并且从页面缓存中清除不太可能在短期内访问的页面。
- FADV_WILLNEED 通知操作系统在不久的将来该进程将需要该页。这为内核提供了提前缓存页面的机会,并且在进行读操作时,可以通过Page Cache而不是Page Fault提供服务。
- FADV_DONTNEED 建议内核可以为相应的页释放缓存(确保数据事先与磁盘同步的情况下)。
- 还有一些标志 (例如_FADV_NOREUSE_),但是在Linux上它不起作用
就像这个标记的名字表达的那样,它只是建议,内核并不能保证一定会像建议的那样执行。
由于数据库开发人员通常可以预测访问,因此 fadvise 是一个非常有用的工具。例如,RocksDB 根据文件类型([[SSTable & LSM Tree|SSTable]] 或 HintFile)、模式(Random 或 Sequential)和操作(Write 或 Compaction)将访问模式通知给内核。
另一个有用的调用是 mlock。它允许您强制将页面保存在内存中。这意味着一旦页面加载到内存中,所有后续操作都将从页面缓存中提供。它必须谨慎使用,因为在每个页面上调用它只会耗尽系统资源。
AIO
最后来谈一谈Linux Asynchronous IO(AIO),AIO 是一个接口,允许启动多个 IO 操作并注册在完成时触发的回调。操作将异步执行(例如,系统调用将立即返回)。在处理提交的 IO 作业时,使用异步 IO 可以帮助应用程序在主线程上继续工作。
负责 Linux AIO 的两个主要系统调用是 io_submit 和 io_getevents。Io_mit 允许传递一个或多个命令,保存一个缓冲区、偏移量和必须执行的操作。可以使用 io_getevents 查询完成,该调用允许为相应的命令收集结果事件。允许使用一个完全异步的接口来处理 IO、流水线 IO 操作和释放应用程序线程,可能会减少上下文切换和唤醒的数量。
不幸的是,Linux AIO 有几个缺点: glibc 没有公开系统调用 API,需要一个库来连接它们(libaio 似乎是最流行的)。尽管多次尝试解决这个问题,但是只支持带有_O_DIRECT_ 标志的文件描述符,因此缓冲的异步操作不会起作用。此外,一些操作,例如 stat、 fsync、 open 和其他一些操作并不是完全异步的。
值得一提的是,Linux AIO 不应该与 Posix AIO 混淆,Posix AIO 完全是另外一回事。Linux 上的 Posix AIO 实现完全在用户空间中实现,根本不使用这个特定Linux子系统。
Vectored IO
还有一个可能不是特别有名的方法来执行IO,Vectored IO(也同样被称为Scatter/Gather)。之所以这样称呼它,是因为它在缓冲区vector上运行,并允许在每次系统调用中使用多个缓冲区从磁盘读取和写入数据。
当执行向量读取时,字节将首先从数据源读入缓冲区(直到第一个缓冲区的长度偏移量)。然后,从第一个缓冲区的长度开始到第二个缓冲区的长度偏移量的字节将被读入第二个缓冲区,以此类推,就好像数据源正在一个接一个地填充缓冲区(尽管操作顺序和并行性不是确定的)。向量写操作的方式与此类似: 缓冲区就像它们在写之前被连接起来那样执行写操作。
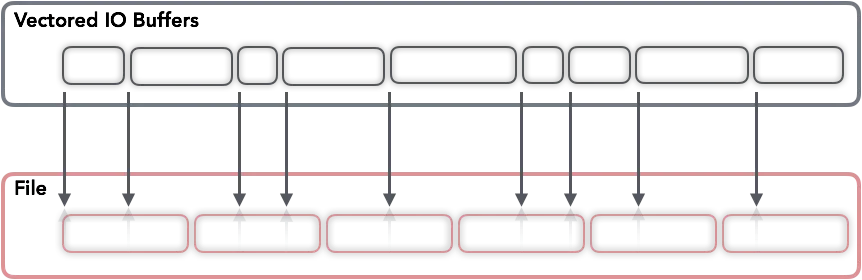
这种方法可以通过允许读取较小的块(从而避免为连续块分配大内存区域)来提供帮助,同时减少用磁盘数据填充所有这些缓冲区所需的系统调用量。另一个优点是读和写都是原子的: 内核防止其他进程在读和写操作期间在同一描述符上执行 IO,从而保证数据的完整性。
从开发的角度来看,如果数据以某种方式布局在文件中(比如说,它被拆分成一个固定大小的头和多个固定大小的块) ,就有可能发出一个调用来填充分配给这些部分的单独缓冲区。
这听起来相当有用,但不知何故,只有少数数据库使用向量 IO。这可能是因为通用数据库同时处理多个文件,试图保证每个正在运行的操作的活性并减少它们的延迟,因此可以按块访问和缓存数据。向量 IO 对于分析工作负载和/或柱状数据库更有用,其中数据连续地存储在磁盘上,其处理可以在稀疏块中并行完成。其中一个例子是 Apache Arrow.