【文献精读】The Power of Prediction: Microservice Auto Scaling via Workload Learning 微服务下的负载预测及资源分配
Apr 14, 2023 - #Research
Metadata
- Authors: Shutian Luo, Huanle Xu, Kejiang Ye, Guoyao Xu, Liping Zhang, Guodong Yang, Chengzhong Xu
- Series: [[SoCC '22]]
- Cite Key: [[@luoPowerPredictionMicroservice2022]]
- Link: The_power_of_prediction_Proceedings_of_the_13th_Symposium_on_Cloud_Computing_2022.pdf
- Bibliography: Luo, S., Xu, H., Ye, K., Xu, G., Zhang, L., Yang, G., & Xu, C. (2022). The power of prediction: Microservice auto scaling via workload learning. Proceedings of the 13th Symposium on Cloud Computing, 355–369. https://doi.org/10.1145/3542929.3563477
- Tags: #microservices, #proactive-auto-scaler, #workload-uncertainty-learning
Abstract
When deploying microservices in production clusters, it is critical to automatically scale containers to improve cluster utilization and ensure service level agreements (SLA). Although reactive scaling approaches work well for monolithic architectures, they are not necessarily suitable for microservice frameworks due to the long delay caused by complex microservice call chains. In contrast, existing proactive approaches leverage end-to-end performance prediction for scaling, but cannot effectively handle microservice multiplexing and dynamic microservice dependencies. In this paper, we present Madu, a proactive microservice auto-scaler that scales containers based on predictions for individual microservices. Madu learns workload uncertainty to handle the highly dynamic dependency between microservices. Additionally, Madu adopts OS-level metrics to optimize resource usage while maintaining good control over scaling overhead. Experiments on large-scale deployments of microservices in Alibaba clusters show that the overall prediction accuracy of Madu can reach as high as 92.3% on average, which is 13% higher than the state-of-the-art approaches. Furthermore, experiments running real-world microservice benchmarks in a local cluster of 20 servers show that Madu can reduce the overall resource usage by 1.7X compared to reactive solutions, while reducing end-to-end service latency by 50%.
Main Content
本工作提出了一种基于单个微服务不确定性分析的OS metric负载预测方案Madu,用以实现微服务场景下的资源分配,以提高资源利用率,保证时延的稳定 ### Madu的背景和贡献
Reactive & Proactive
Reactive的资源调整方法对于微服务框架来说是不可行的,因为微服务的调用链非常复杂,会产生很长的延迟效应,而现有的Proactive的方法也同样没有考虑到微服务的复用性(microservice multiplexing) 和动态依赖性(mircroservice dependencies)。
Q:在微服务下, 为什么Reactive的scaling方法不work? A: 1. 微服务处理服务请求的调用链可能非常长,这种情况下,调用链底端的微服务可能需要很长时间才会经历负载的变化,而当它观测到负载变化时,可能已经为时过晚了。 2. scaling微服务通常需要从仓库拉去images,这个操作需要数秒来完成,而在线服务的SLAs通常是用几百微秒来定义的,因此reactive的方法常常会导致SLA侵犯。
Q:现有的Proactive的scaling方法为什么不能有效的应用于微服务场景?
今的微服务预测通常是基于依赖图来进行预测,这种方法没有考虑微服务的两个核心特征:
1.
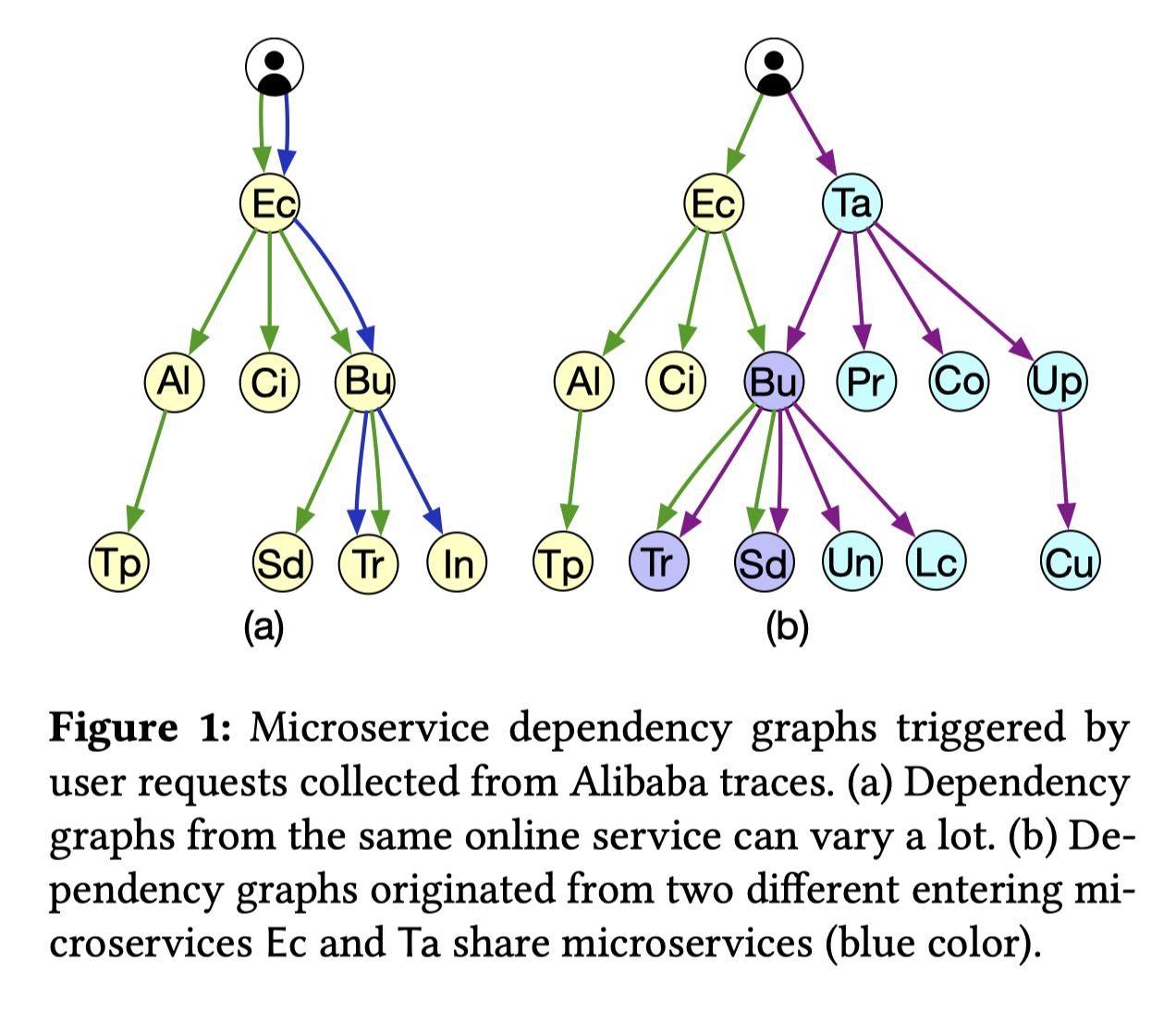
同一个在线服务可能会产生完全不同拓扑结构的调用图,这种高度动态的特征使得基于图的训练难以在实际中使用(Fig1
(a): Dynamic
dependencies),现有的proactive的autocaling的方法都是基于静态图的所以效果不会好。
2.
单个的microservice可能会被多个在线服务复用,如果独立的训练所有的调用图可能难以解决微服务复用的问题(Fig1
(b): Shared
microservices),一种方法是组合单个服务图形成一个组合图,但是这种方法的可扩展性比较差,因为生产环境通常会包含成千上万个微服务。
Data-dependent Uncertainty
一个微服务负载除了有周期特征之外,还有很强的[[Data-depentent Uncertainty]]。本文给出的Data-dependent Uncertainty的解释是
That is, peak workloads have much higher variance across different periods (relative to the mean workload) than other workloads due to the dynamic dependency between microservices.
其实这个所谓的Data-depentent Uncertainty并不是微服务独有的,关于这个部分,非常值得深入研究。因为时序预测中这个现象非常普遍,需要去 找一下有没有什么更先进的方法能解决这种不确定性问题。
微服务负载的不确定性
本工作将负载定义为每分钟调用次数(Call Per minute, CPM)
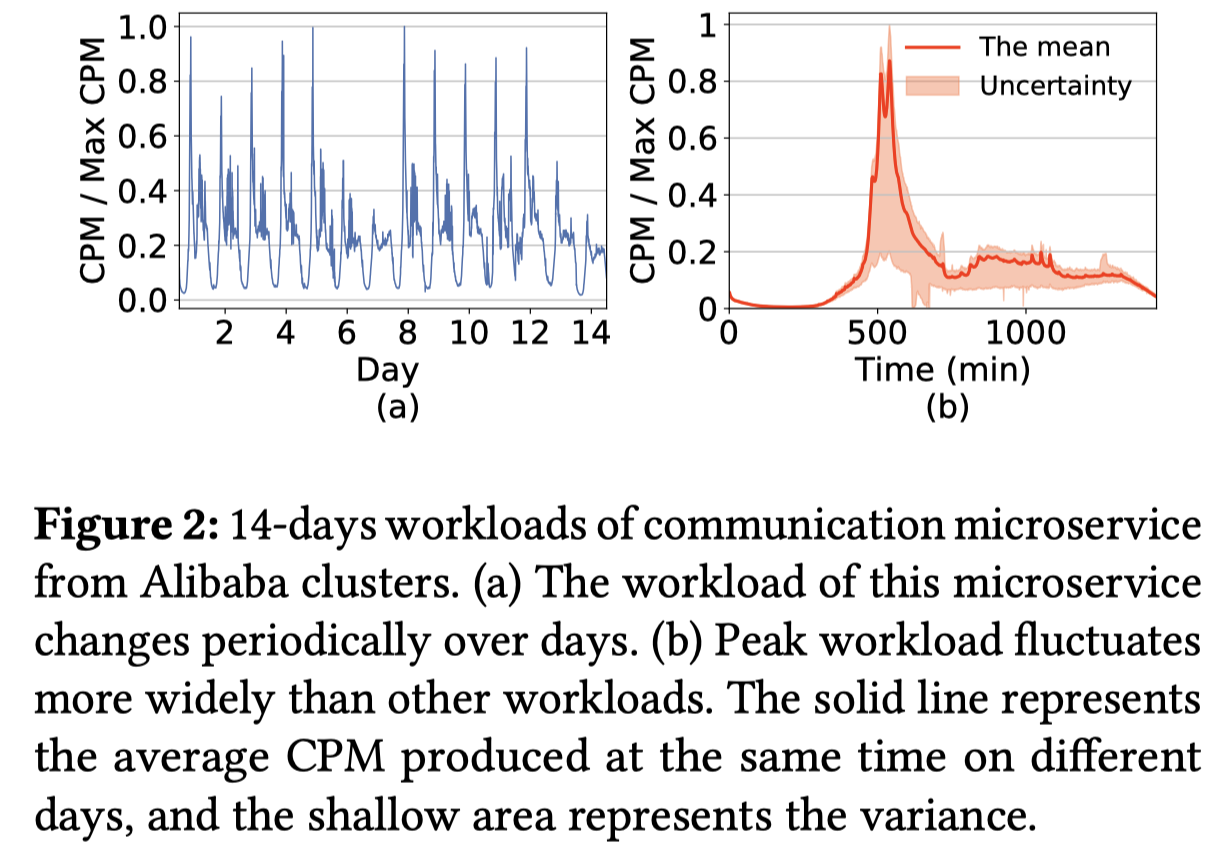
- 微服务的负载有着周期特征,例如说,在工作日的时候峰值总是在同一时间出现(Fig 2 (a))
- 然而,微服务的负载也有着非常强的[[Data-depentent Uncertainty]],也就是说,负载在不同周期内的方差与平均负载有关。(Fig 2(b))所示,对于通信微服务,其在不同工作日的峰值工作负载比其他服务的负载具有更高的方差。本文通过计算在30天内不同周期内工作负载(相对于平均工作负载)的方差来量化阿里巴巴集群中每个微服务的工作负载不确定性
- 由[[luoCharacterizingMicroserviceDependency2021|阿里巴巴微服务trace分析]]可知,微服务的动态依赖性与微服务的不确定性有很强的相关性,不同的微服务的动态依赖不同,因此不确定性不是统一的
微服务性能指标
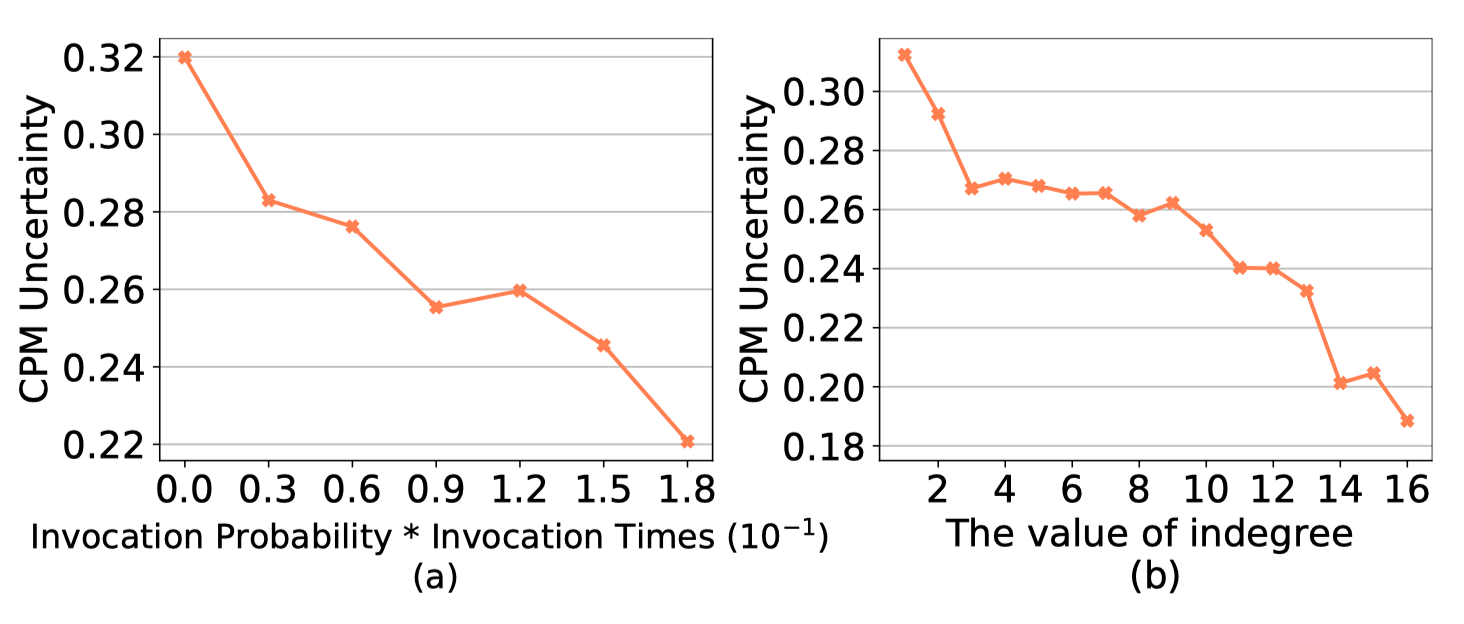
 CPU和内存利用率与微服务工作负载的相关性比微服务响应时间更强。因此,Madu转而使用这些操作系统级别的指标来评估微服务的性能以进行资源扩展
CPU和内存利用率与微服务工作负载的相关性比微服务响应时间更强。因此,Madu转而使用这些操作系统级别的指标来评估微服务的性能以进行资源扩展
本文的贡献
- 设计了一个新的模型来学习微服务负载的不确定性,它可以捕捉微服务间动态的负载以及克服低谷高峰负载的情况
- 实现了一种新的proactive的微服务资源自动缩放器,可以以很低的开销实现高效的缩放微服务容器
- 执行了真实负载重放(Alibaba)来验证负载预测的能力 论文提出的Madu是一个以容器为粒度的资源自动缩放器,它能够同时学习微服务负载的均值和不确定性,并且精妙的结合这两个部分以产生更加精确的预测结果。
系统总体设计
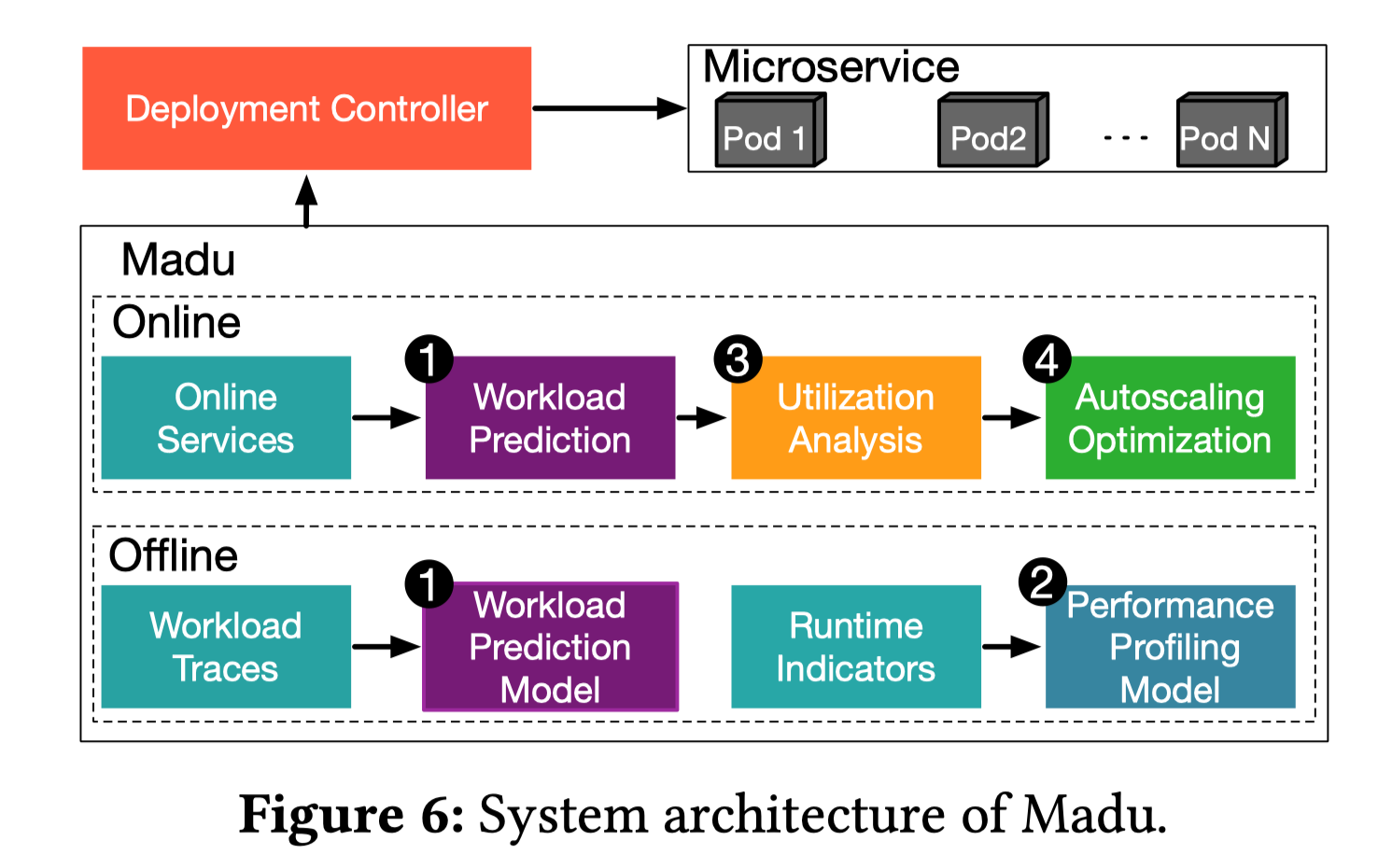
Auto-scaler独立于微服务集群运行,在每一分钟的开始,它会向
- Workload Predictor查询未来会被发送至每个微服务的调用次数(预测的负载)
- Auto-scaler会使用Utilization Analysis来决定每一个时间区间内的需要部署的初始容器数量以控制CPU和内存利用率
- 每个微服务的初始资源利用情况估计是由Performance Profiling Model完成的,但是由于微服务负载震荡得很厉害,所以并不会实际使用这个初始的决策
- 初始决策被发送至Autoscaling Optimization来决定最后需要缩放的容器数量,它会保证不会频繁的调动资源
Madu的设计与实现
微服务负载学习
Madu不是基于微服务间的依赖来学习负载的,因为生产环境下有成百上千的微服务之间存在依赖,这样会引入相当大的开销
Madu是基于[[seq2seq]]的,Madu针对其主要有两个改进:
- 提出了一种新的损失函数
- 引入了随机注意力机制(stochastic [attention] mechanism)
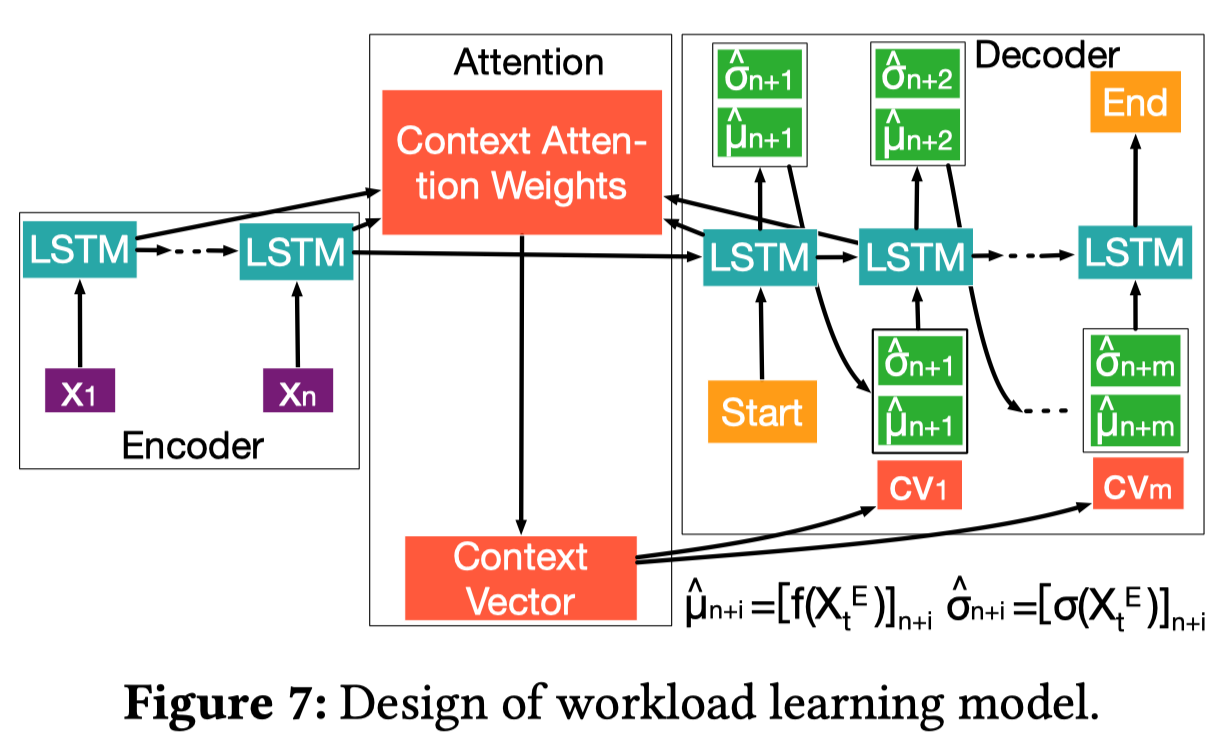
模型输入(Encoder):长度为n的向量\(\boldsymbol{X}_t^E=\left[x_{t-n+1}, x_{t-n+2}, \cdots, x_t\right]\) 模型输出(Decoder):长度为m的向量\(\boldsymbol{X}_t^D=\left[x_{t+1}, x_{t+2}, \cdots, x_{t+m}\right]\) 其中的每一个\(x_i={C_t,t_m,t_h,t_w}\),\(C_t\)表示\(t\)时刻的CPM,而\(t_m,t_h,t_w\)分别表示分钟、小时和星期,送入时间特征让模型能够学习到时序信息,n和m的值是训练准确率和scaling效率的tradeoff
- 似然函数:由于data-depentent uncertainty的存在,需要假设\(\boldsymbol{X}_t^D=f(\boldsymbol{X}_t^E)+\epsilon(\boldsymbol{X}_t^E)\),其中\(\epsilon\)属于(0 1)正态分布,因此似然函数可以定义为\(p\left(\boldsymbol{X}_t^D \mid \boldsymbol{X}_t^E, \boldsymbol{W}\right)=\exp \left(-\frac{\left(\boldsymbol{X}_t^D-f\left(\boldsymbol{X}_t^E\right)\right)^2}{2 \sigma^2\left(\boldsymbol{X}_t^E\right)}\right) / \sqrt{2 \pi \sigma^2\left(\boldsymbol{X}_t^E\right)}\),其中\(f(.)\)和\(\epsilon(.)\)为seq2seq模型拟合的函数,学习过程中模型需要调整参数\(\boldsymbol{W}\)来极大似然函数
- 随机注意力机制:注意力分数\(S\)是从一个高斯分布中采样来的,这个高斯分布是基于\(\boldsymbol{X}_t^E\) (for data-dependent uncertainty)和参数\(\boldsymbol{W}\)的,引入了注意力机制之后,预测结果就可以表示为\(\left[\widehat{\mu}_{t+1}, \widehat{\sigma}_{t+1}\right]=\left[f\left(\widehat{\mu}_t, \widehat{\sigma}_t, h_t, c_t, c v_t\right), \sigma\left(\widehat{\mu}_t, \widehat{\sigma}_t, h_t, c_t, c v_t\right)\right]\)了,两个函数的前4项是普通LSTM的组件,而\(cv_t\)由注意力机制产生 \[ \begin{gather} cv_t=\sum_{j=1}^{n}a_{tj}h^E_t \\ \alpha_{t j}=\frac{\exp \left(s_{t j}\right)}{\sum_{k=1}^n \exp \left(s_{t k}\right)} \\ s_{t j}=f\left(a_{t j}\right), a_{t j}=\tanh \left(W_a h_{t-1}+U_a h_j\right) \end{gather} \]
对于\(s_{t j}=f\left(a_{t j}\right)\),非随机的注意力机制通常假定\(f\)是一个线性函数,而对于随机注意力机制,则是从一个高斯分布\(s_{t j} \sim \mathbf{N}\left(\mu_{t j}, \sigma_{t j}\right)\)中采样得到的,其中\(\mu_{tj}=W_{\mu j}a_{tj}+b_{\mu j}, \sigma_{tj}=W_{\mu j}a_{tj}+b_{\sigma j}\),4个\(W\)和\(b\)是由模型学习的参数
微服务性能建模
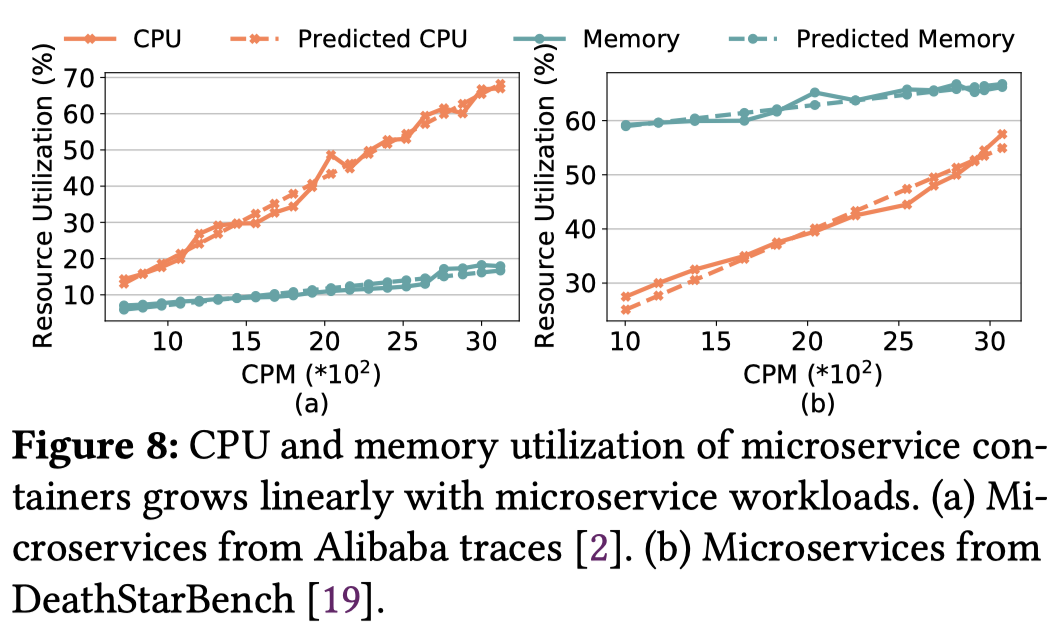
通过刻画内存利用率以及CPU利用率与CPM的关系可以发现,它们几乎是线性相关的,因此拟合两个线性回归模型就可以了
在线容器缩放以及缩放优化
根据Performance Profiling拟合出来的线性函数、及Workload Predictor预测的CPM值以及预定的CPU和内存利用率阈值,可以计算出之后m个时间区间内所需要的容器数量,但是同时为了避免大量的调整容器数量(调整容器也同样需要消耗资源并且需要一定的时间),还需要做出一些限制,具体的,需要解决一个最优化问题: \(\begin{aligned} & \min _{\boldsymbol{x}_i} \sum_{k=1}^m\left(x_i(t+k-1)-x_i(t+k)\right)^2 \\ & \text { s.t., } c_i(t+k) \leq x_i(t+k) \leq(1+\rho) \cdot c_i(t+k) .\end{aligned}\) 其中\(c_i\)表示微服务i的容器数量,\(\rho\)是一个预先定义的常量,这是一个[[凸优化问题]], Madu使用[[CVX sovler]]来解
验证与性能表现
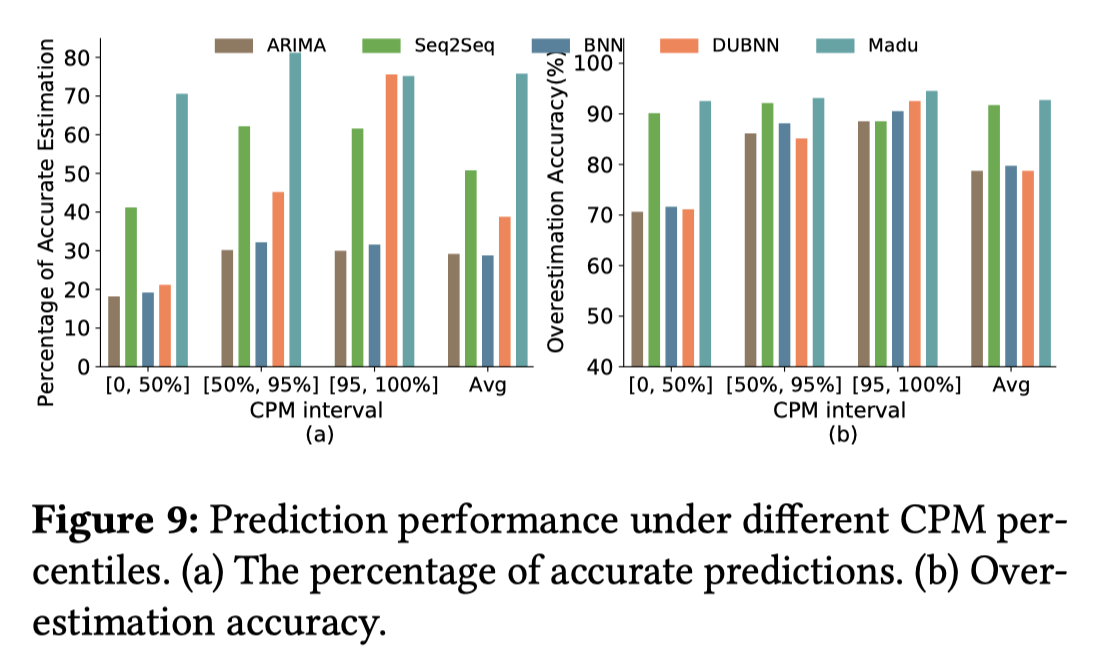
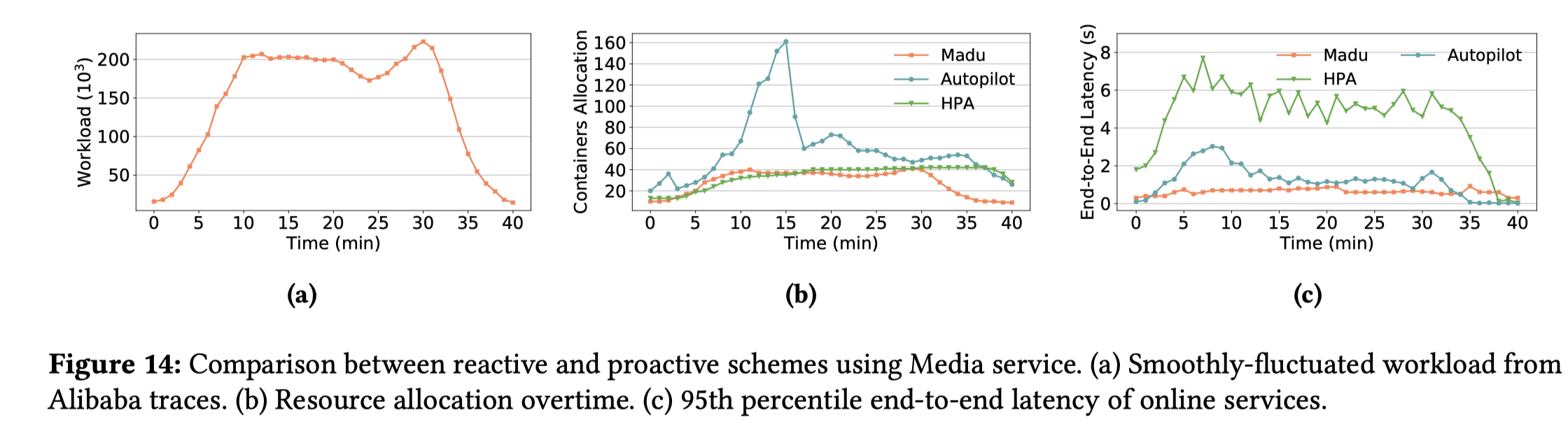
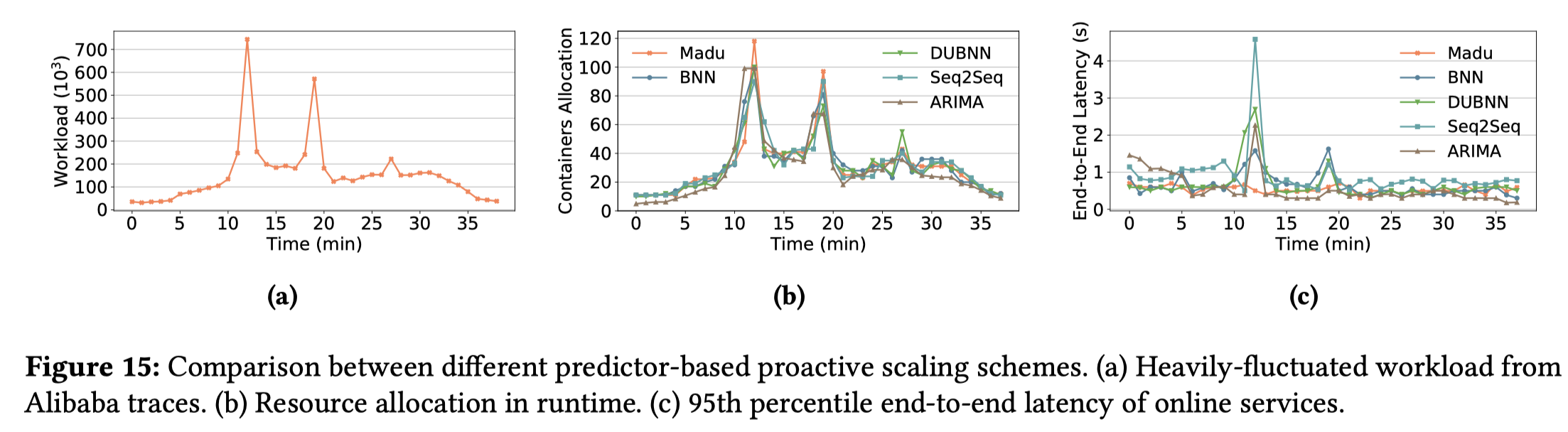
Madu和其他4种算法进行了对比,分别为ARIMA、Seq2Seq、BNN、DUBNN,值得注意的是,在高负载的情况下,DUBNN的表现也很好,但是DUBNN的训练成本要远高于Madu,并且文章解释DUBNN和BNN都需要一个先验估计,这个先验估计选取得不恰当的话会严重影响性能 整体表现上:
- 低负载情况下,Madu可以将预测准确性提高到90%以上。
- 高负载情况下,Madu比DUBNN要高出1个百分点,这说明Madu有处理突发负载的能力单个表现上(对于预测非常精确的样本(1±10%)*ground
truth):-
Madu在低负载情况的表现也没有很好,但是超过了其他算法很多,这是由于Madu仍然会因为不确定性学习做出过度估计
Appendix
Reading List
Reactive Autoscaling
- Alim Ul Gias, Giuliano Casale, and Murray Woodside. 2019. ATOM:Model-Driven Autoscaling for Microservices. In Proceedings of ICDCS.
- Ram Srivatsa Kannan, Lavanya Subramanian, Ashwin Raju, Jeongseob Ahn, and Jason Mars. 2019. GrandSLAm: Guaranteeing SLAs for Jobs in Microservices Execution Frameworks. In Proceedings of EuroSys.
- Amirhossein Mirhosseini, Sameh Elnikety, and Thomas F Wenisch. 2021. Parslo: A Gradient Descent-based Approach for Near-optimal Partial SLO Allotment in Microservices. In Proceedings of SoCC.
- Guangba Yu, Pengfei Chen, and Zibin Zheng. 2019. Microscaler: Automatic Scaling for Microservices with an Online Learning Approach. In Proceedings of ICWS.
- Laiping Zhao, Yanan Yang, Kaixuan Zhang, Xiaobo Zhou, Tie Qiu, Keqiu Li, and Yungang Bao. 2020. Rhythm: component-distinguishable workload deployment in datacenters. In Proceedings of EuroSys.
Proactive Autoscaling
- Vivek M Bhasi, Jashwant Raj Gunasekaran, Prashanth Thinakaran, Cyan Subhra Mishra, Mahmut Taylan Kandemir, and Chita Das. 2021. Kraken: Adaptive Container Provisioning for Deploying Dynamic DAGs in Serverless Platforms. In Proceedings of SoCC.
- Ka-Ho Chow, Umesh Deshpande, Sangeetha Seshadri, and Ling Liu. 2022. DeepRest: Deep Resource Estimation for Interactive Microservices. In Proceedings of EuroSys.
- Yu Gan, Yanqi Zhang, Kelvin Hu, Dailun Cheng, Yuan He, Meghna Pancholi, and Christina Delimitrou. 2019. Seer: Leveraging Big Data to Navigate the Complexity of Performance Debugging in Cloud Microservices. In Proceedings of ASPLOS.
- Haoran Qiu, Subho S. Banerjee, Saurabh Jha, Zbigniew T. Kalbarczyk, and Ravishankar K. Iyer. 2020. FIRM: An Intelligent Fine-grained Resource Management Framework for SLO-Oriented Microservices. In Proceedings of OSDI.
Workload Learning
- Marcus Carvalho, Walfredo Cirne, et al. 2014. Long-term SLOs for reclaimed cloud computing resources. In Proceedings of SoCC.
- Lin Ma, Dana Van Aken, et al. 2018. Query-based workload forecasting for self-driving database management systems. In Proceedings of SIGMOD.
- Ashraf Mahgoub, Alexander Medoff, Rakesh Kumar, Subrata Mitra, Ana Klimovic, Somali Chaterji, and Saurabh Bagchi. 2020. OPTIMUSCLOUD: Heterogeneous Configuration Optimization for Distributed Databases in the Cloud. In Proceedings of ATC.
- Hiep Nguyen, Zhiming Shen, et al. 2013. AGILE: Elastic Distributed Resource Scaling for Infrastructure-as-a-Service. In Proceedings of ICAC.
- Zhiming Shen, Sethuraman Subbiah, et al. 2011. Cloudscale: elastic resource scaling for multi-tenant cloud systems. In Proceedings of SoCC.
Microservice Study
- Shutian Luo, Huanle Xu, Chengzhi Lu, Kejiang Ye, Guoyao Xu, Liping Zhang, Jian He, and Cheng-Zhong Xu. 2022. An In-depth Study of Microservice Call Graph and Runtime Performance. IEEE Transactions on Parallel and Distributed Systems (2022).
attention
- Jay Heo, Hae Beom Lee, et al. 2018. Uncertainty-aware attention for reliable interpretation and prediction. In Proceedings of NeurIPS.
- Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. 2015. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of ICML.
Autoscaling
- Kubernetes Horizon Pod Autoscaler. https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/.
- Ataollah Fatahi Baarzi and George Kesidis. 2021. Showar: Right-sizing and efficient scheduling of microservices. In Proceedings of the ACM Symposium on Cloud Computing.
- Md Rajib Hossen, Mohammad A Islam, and Kishwar Ahmed. 2022. Practical Efficient Microservice Autoscaling with QoS Assurance. In Proceedings of HPDC