【文献精读】FIRM: An Intelligent Fine-Grained Resource Management Framework for SLO-Oriented Microservices 微服务下基于关键节点提取和强化学习的的细粒度资源管理框架
Jun 8, 2023 -
Metadata
- Authors: Haoran Qiu, Subho S Banerjee, Saurabh Jha, Zbigniew T Kalbarczyk, Ravishankar K Iyer
- Cite Key: [[@qiuFIRMIntelligentFineGrained]]
- Link: FIRM_.pdf
- Bibliography: Qiu, H., Banerjee, S. S., Jha, S., Kalbarczyk, Z. T., & Iyer, R. K. (n.d.). FIRM: An Intelligent Fine-Grained Resource Management Framework for SLO-Oriented Microservices.
Abstract
User-facing latency-sensitive web services include numerous distributed, intercommunicating microservices that promise to simplify software development and operation. However, multiplexing of compute resources across microservices is still challenging in production because contention for shared resources can cause latency spikes that violate the servicelevel objectives (SLOs) of user requests. This paper presents FIRM, an intelligent fine-grained resource management framework for predictable sharing of resources across microservices to drive up overall utilization. FIRM leverages online telemetry data and machine-learning methods to adaptively (a) detect/localize microservices that cause SLO violations, (b) identify low-level resources in contention, and (c) take actions to mitigate SLO violations via dynamic reprovisioning. Experiments across four microservice benchmarks demonstrate that FIRM reduces SLO violations by up to 16× while reducing the overall requested CPU limit by up to 62%. Moreover, FIRM improves performance predictability by reducing tail latencies by up to 11×.## Annotations
Main Content
本文提出了FIRM,一个智能的、细粒度的资源管理框架,用以预测不同微服务之间的共享资源,以提升整体的利用率。FIRM使用在线遥测技术和机器学习方法来适应性的:
- 检测和定位触犯SLO的微服务
- 识别竞争中的低级资源
- 通过动态分配以缓解SLO触犯 其主要贡献有:
- 提出了一种基于[[SVM]]的SLO触犯定位方法
- 给予强化学习的SLO触犯缓解措施,并且能够通过使用 tranfer learning 为单个微服务实例调优定制的 RL 代理
- 在线的训练以及性能异常注入,人工创造资源竞争的情况,由此来构造训练集
- 实现和验证,开源了针对k8s的FIRM框架,并且在四个真实微服务benchmark上进行了测试
FIRM 框架
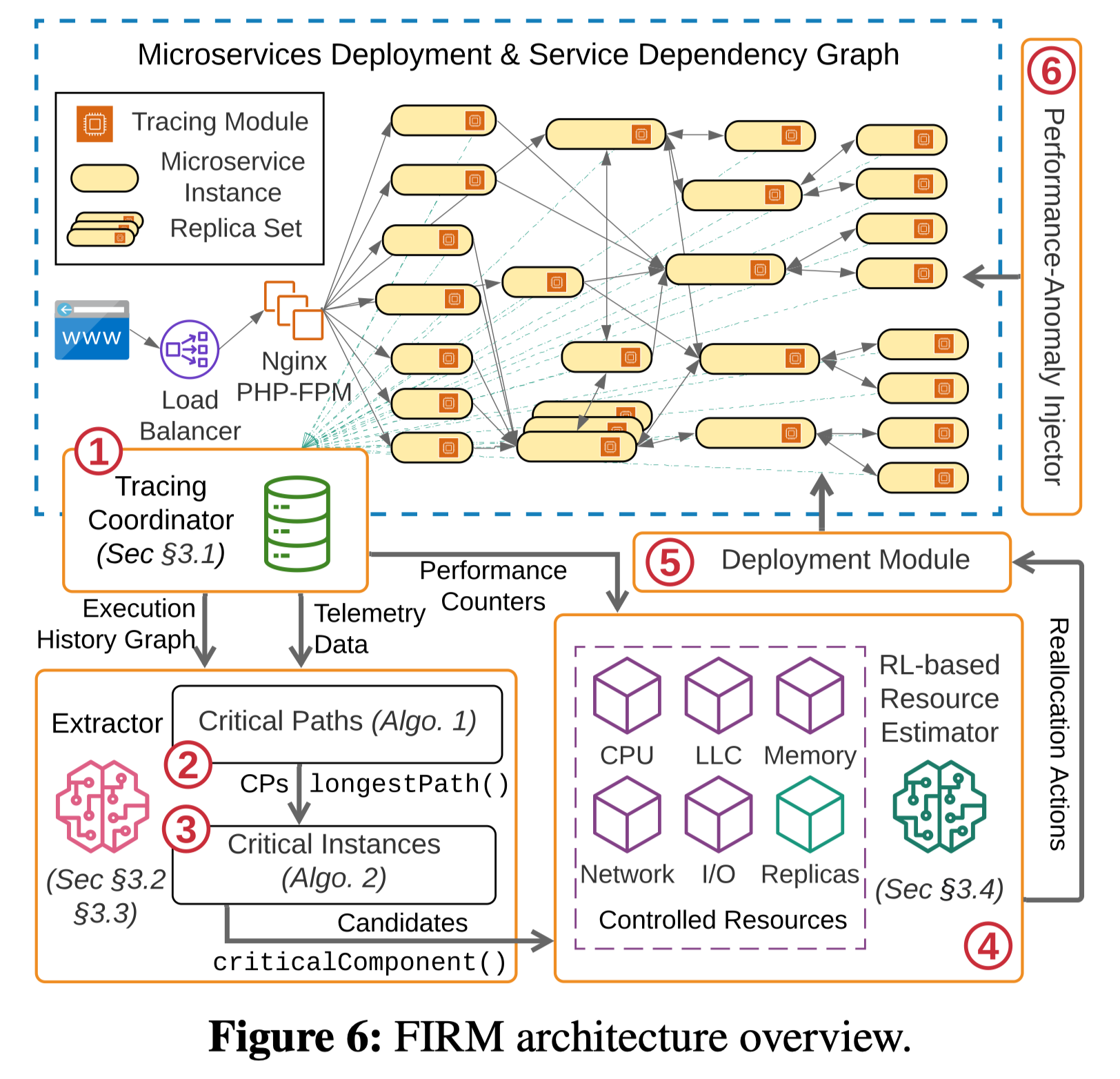
- Tracing Coordinator:负责收集负载和遥测数据(资源数据,1)并将它们存储在一个中心化的图数据库中,以监测关键路径的变化并从中抽取出关键微服务实例
- Extractor:监测SLO触犯,向Tracing Coordinator查询抽取出的CP(2)并定位关键的SLO触犯根因微服务实例(3)
- RL-based Resource Estimator:通过监测数据(1)以及关键实例(3),FIRM通过强化学习模型来向关键实例重新分配资源,RL模型会综合考虑资源利用率的上下文信息(例如底层资源CPU、LLC、内存以及网络),性能信息(例如每个微服务的以及端到端的延时分布)以及负载特征(例如请求速率以及成分)等来进行决策
- Deployment:动作被验证和执行,以在底层为k8s的集群上部署
- Performance Anomaly Injection:为了更好的训练机器学习模型和强化学习智能体(扩展exploration-exploitation space),FIRM通过主动引发资源竞争来生成SLO触犯 ### Tracing Coordinator FIRM实现一个分布式Tracing,用于构建excution history graph。span是指一个微服务实例处理一次请求所需要的时间,它是基于请求达到微服务到其发送恢复给调用者的时间计算的
FIRM的实现受到了Jaeger的启发,每一个微服务实例都伴有一个OpenTracing组件用以追踪和计算span,因此任何伴有OpenTracing组件的微服务都能自然的集成进FIRM的tracing框架。
Tracing Coordinator作为一个无服务的、多副本的数据处理组件运行在系统中,其造成的负荷可以忽略不计(小于0.4%的带宽损失和小于0.15%的延时损失)
Critical Path Extractor&Critical Component Extractor
使用算法1可以在execution history
graph中抽取出关键路径,算法1的核心是一个权重最长路径算法,它需要同时考虑微服务架构中的通讯和计算特征(Parallel、Sequential、Background)
 在此之后,FIRM在每个抽取出来的CP中使用一个适应性强的、数据驱动的方法来决定关键成分(微服务实例),整个过程如算法2所示。算法首先计算每一个CP和每一个实例的“特征”,表示性能的变化和拥塞程度,记者这两种特征被喂入一个SVM分类器得到二分类结果(即实例是否应该改变其资源进行重新分配)
在此之后,FIRM在每个抽取出来的CP中使用一个适应性强的、数据驱动的方法来决定关键成分(微服务实例),整个过程如算法2所示。算法首先计算每一个CP和每一个实例的“特征”,表示性能的变化和拥塞程度,记者这两种特征被喂入一个SVM分类器得到二分类结果(即实例是否应该改变其资源进行重新分配)
为了达到这个目的,需要从两个方面考虑:端到端延时的变化以及单个微服务由于服务队列导致的竞争而发生的变化:
- Per-CP Variability:皮尔森相关系数衡量单个微服务延时对于整个端到端延时的影响力
- Per-Instance
Variablity:单个微服务的拥塞强度(定义为p-99延时和延时中位数之比)
 ### Resource Estimator
传统的基于性能建模和启发式的方法都存在两个问题:
### Resource Estimator
传统的基于性能建模和启发式的方法都存在两个问题:
- 它们没有考虑系统状态的动态性
- 设计、实现和验证方法需要专家知识,并且需要同时掌握微服务负载特征和底层架构 强化学习在探索动作空间和生成最优策略时提供了紧密的反馈,且不需要依赖一个不准确的假设(启发式或者规则)
FIRM采用[[DDPG算法]]来进行强化学习
critic网络和actor网络结构如下图所示,actor网络有8个输入和5个输出,critic网络有23个输入和1个输出,它们的输入输出含义由表3所示
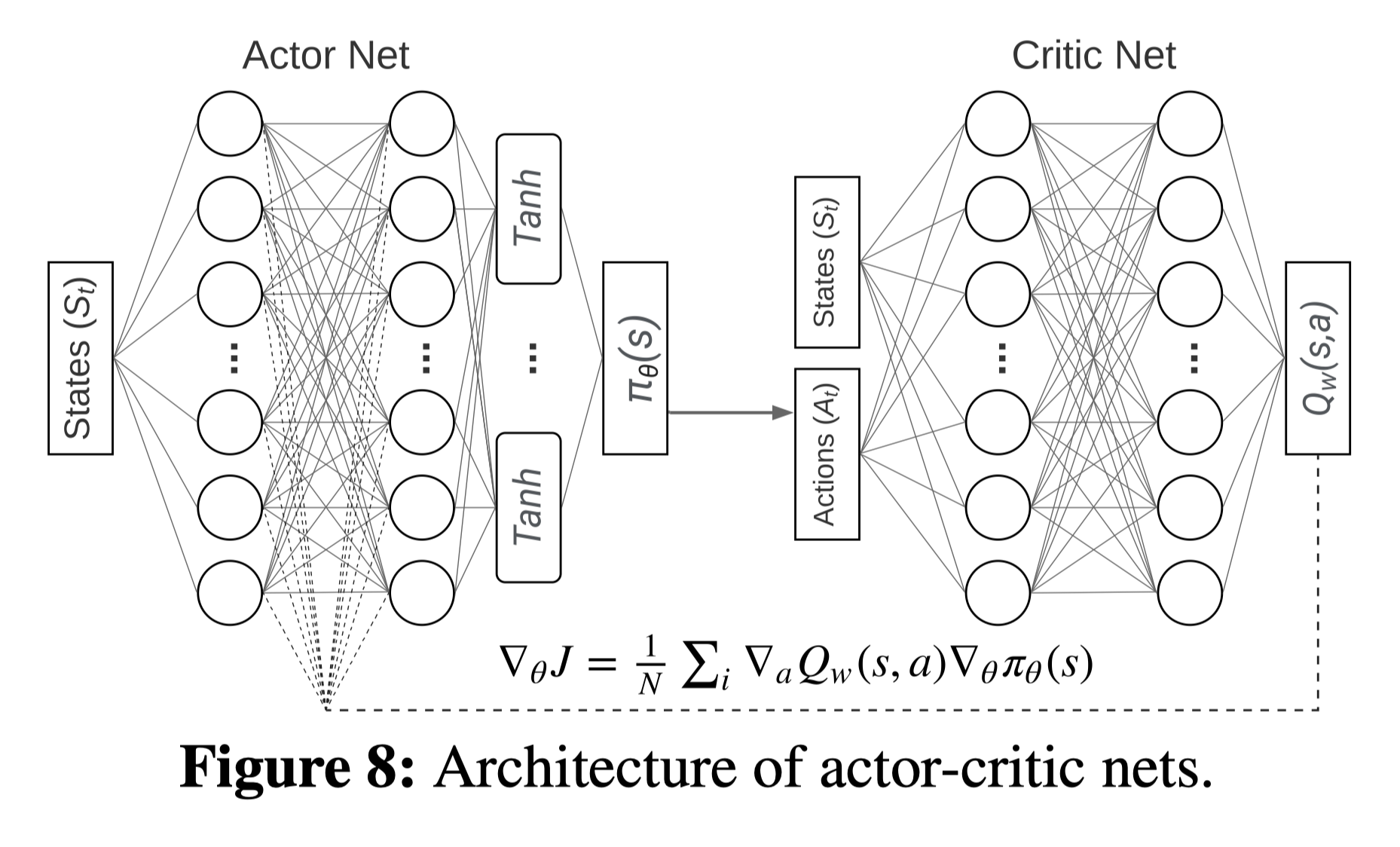
在每一个迭代步中,每一种资源的利用率\(RU_t\)是通过Tracing
Coordinator获得的遥测数据(table
2)得到的,除此之外,Extractor还有收集当前的延时、请求到达速率以及请求构成(当前请求的种类),强化学习智能体会根据这些数据计算状态(table
3) 

- \(SM_t\):若微服务实例被定为罪魁祸首则定义为\(SLO\_Latency/current\_latency\),如果没有消息到达,则设定为没有SLO触犯(\(SM_t=1\))
- \(WC_t\):定义为当前的到达率和前一个时间戳到达率的比
- \(RC_t\)定义为一个唯一的值,从一个请求占比数组中编码而来(使用numpy包)
FIRM通过transfer learning来解决为每个微服务定制模型造成的庞大时间开销
Action Execution
FIRM假设物理机资源是无穷的,因此没有设计准入和节流策略,如果一个动作会导致资源撑爆了,那么它会被替代为一个scale-out操作
- CPU动作:通过cgroups的
cpu.cfs_period_us和cpu.cfs_quota_us实现 - 内存动作:通过Intel MBA和Intel CAT技术来控制内存带宽和LLC容量
- I/O动作:使用cgroup中的
blkio来控制 - 网络动作:使用HTB队列控制
Performance Anomaly Injector
通过异常注入引发SLO违背可以加速训练过程并且扩展强化学习在不利的资源竞争的空间中探索(也就是所说的exploration-exploitation
trade off)
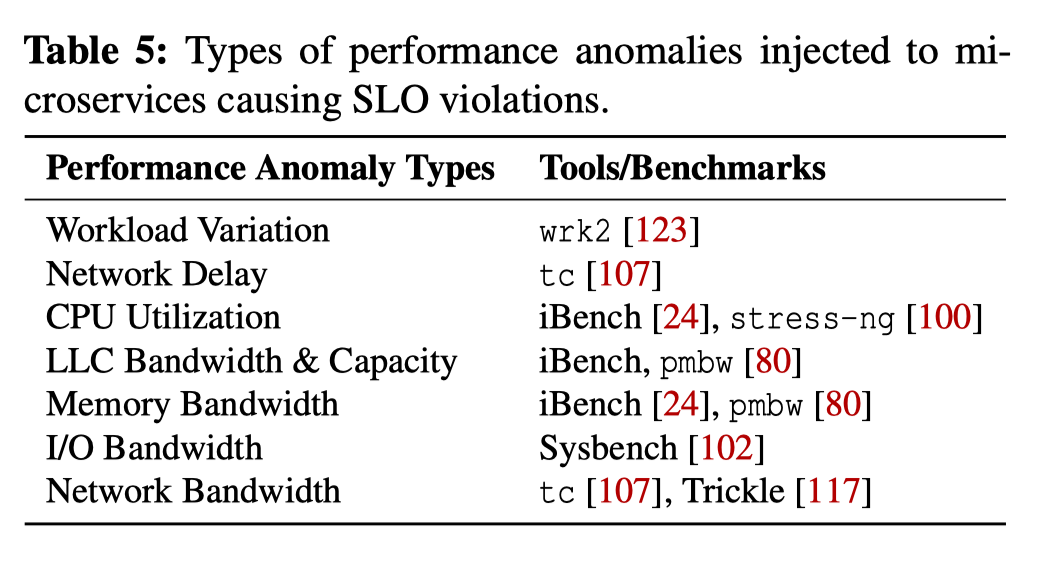
异常注入通过将二进制文件绑定到每一个容器的操作系统层实现,并且可以远程触发,而且可以随时控制注入目标,异常种类,注入时间、区间、模式和强度,注入由7种可能触发SLO违背的性能异常构成
Details
FIRM缓解SLO触犯时不会过度分配, 这是因为:
- 它将底层资源和应用性能之间的依赖通过基于强化学习的反馈回路进行建模,以解决不确定性和存在的噪声
- 它使用了一个两层的方法,在线关键路径分析和SVM模型仅仅过滤出那些需要被考虑的微服务,因此使得应用框架无关并且使得强化学习代理训练更加快速 ### Critical Path(CP) 微服务\(m\)的一个 critical path(CP) 定义为由用户请求启动的,并且以微服务\(m\)结束的最长调用路径,而如果单独说CP而不提任何微服务,那么CP就指代端到端延时
通过在开源数据集上进行大量的异常注入实验,有了如下的发现: 1.
CP的行为是动态的,因为底层的共享资源会发生竞争 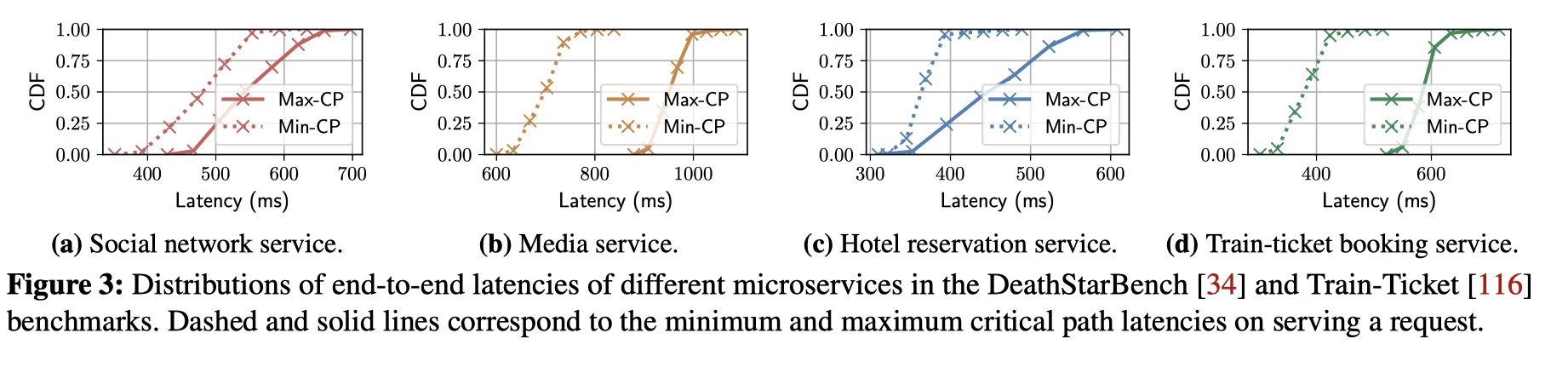 2.
有着较大负载的个体微服务通常不是导致触犯SLO的罪魁祸首,但是文章假设罪魁祸首一定在CP上(?)
2.
有着较大负载的个体微服务通常不是导致触犯SLO的罪魁祸首,但是文章假设罪魁祸首一定在CP上(?)
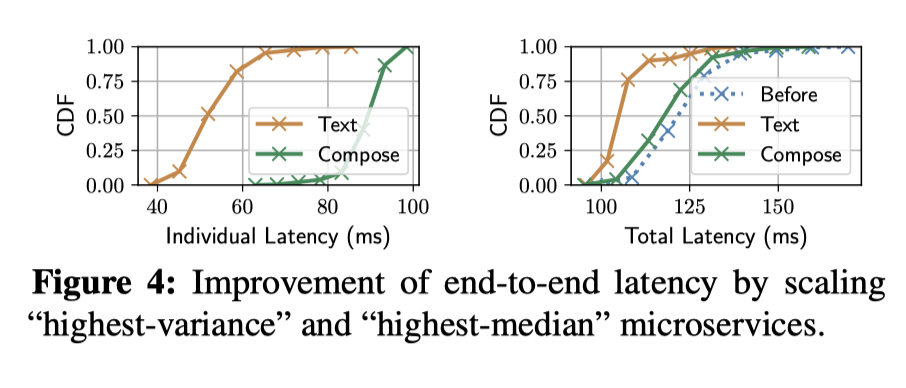 3.
缓解SLO触犯的策略要根据用户负载和资源竞争情况不同而发生变化 1.
一般来说,通常有两种办法可以向关键微服务提供更多资源 1. scale
out:在集群的另一个node上启动一个新的容器实例 2. scale
up:向已存在的容器显式地划分更多资源(例如内存带宽和最后一级缓存)提供更多的CPU核
2. scale out和scale up之间的trade
off不仅取决于用户负载,同样也取决于资源类别
3.
缓解SLO触犯的策略要根据用户负载和资源竞争情况不同而发生变化 1.
一般来说,通常有两种办法可以向关键微服务提供更多资源 1. scale
out:在集群的另一个node上启动一个新的容器实例 2. scale
up:向已存在的容器显式地划分更多资源(例如内存带宽和最后一级缓存)提供更多的CPU核
2. scale out和scale up之间的trade
off不仅取决于用户负载,同样也取决于资源类别 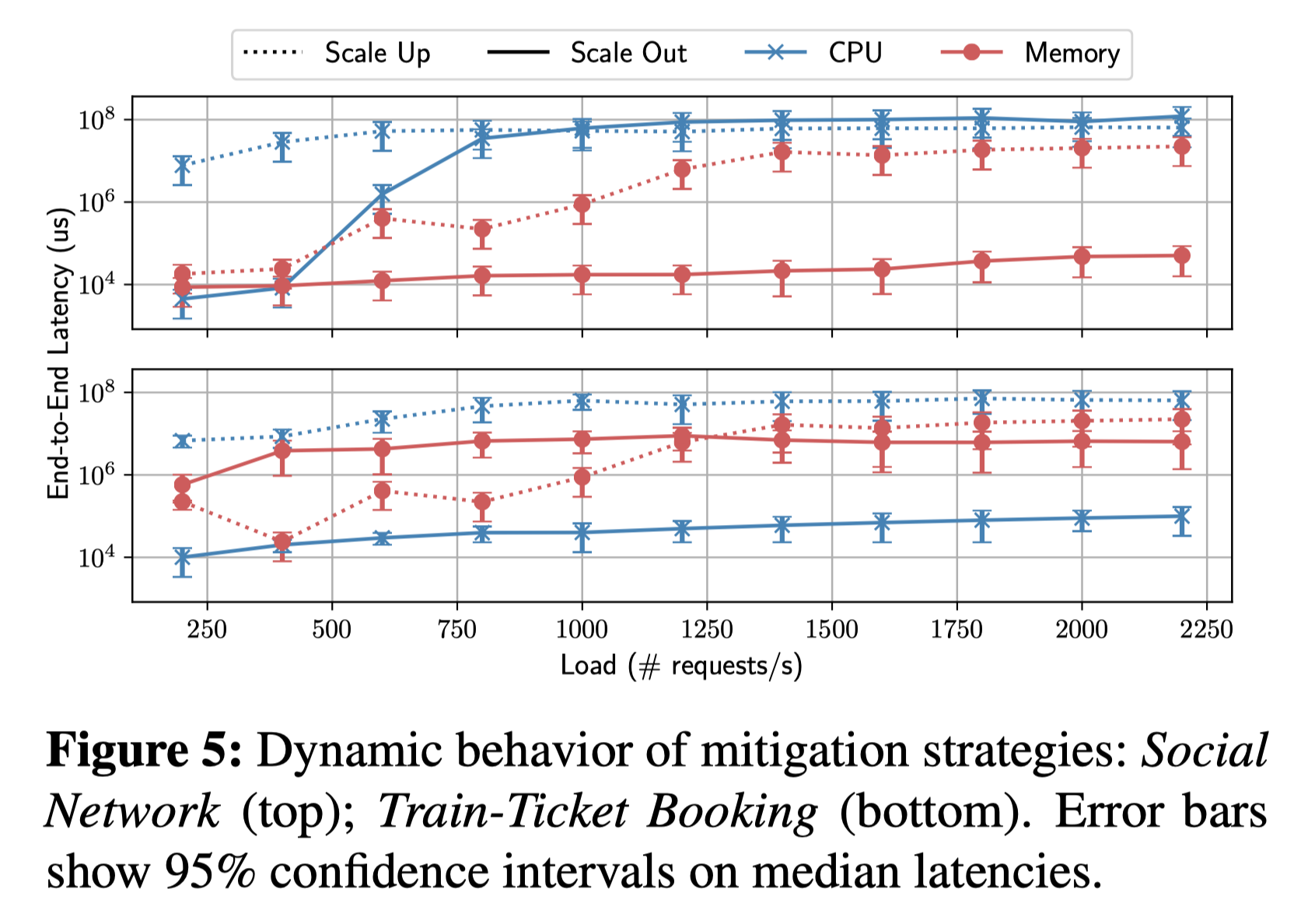
⬆ #Method Benchmark, #Microservice, #Reinforcement Learning, #Resource Management